We (Cambridge Semantics) have recently launched a new blog, Enterprise Semantics. The blog covers a mix of technical and business topics related to the use of semantic technologies inside large enterprises. I'm writing some posts on that blog, and I'll be continuing to put posts here as well. You can sign up to follow the blog in an RSS reader via its feed, or you can receive emails when there are new posts by subscribing on the blog itself, or you can just follow us @CamSemantics. (The feed is not currently syndicated by Planet RDF, so if you read my blog via Planet RDF and are interested in enterprise semantics, you should probably still sign up separately.)
Here's just a taste of some of the content we've published in the first two months of the blog:
What Happened to NoSQL for the Enterprise?
So what it comes down to is that for decades we’ve had one standard way to store and query important data, and today there are new choices. As with any choice, there are tradeoffs, and for some applications NoSQL databases, including Semantic Web databases, can enable organizations to get more done in less time and with less hardware than relational databases. The trick is to know when and how to deploy these new tools.
Big Data... or Right Data?
What matters most, Big Data or Right Data? One look at all the IT headlines these days would suggest that Big Data is the most important data issue today. After all, with lots of computing power and better database storage techniques it is now practical to analyze petabytes of data. However, is that really the most compelling need that end users have? I don’t think so. Instead, I would claim that the issue most end users have is getting together the right data to help them do their jobs better, not analyzing billions of individual transactions.
What the Semantic Web and Digital Cameras have in Common
Analog photography went through lots of phases of dramatic improvement, becoming a mass-market technology. But...no matter how far it went it was limited in its flexibility. Every picture was pretty much as you took it. Any modification required real experts, with specialist equipment and working in a dark room. With the advent of digital photography we have achieved extreme flexibility. The picture you take is simply the starting point to create the picture you want, and the end users themselves can make the changes with easy to use tools.
Semantic Web technology represents the same dramatic shift from the traditional technologies.
Why Semantic Web Software Must Be Easy(er) to Use
In short, if Semantic Web software is hard to use, then many of the benefits of using these technologies in the first place are immediately lost. Conversely, if Semantic Web software is easy to use, on the other hand, then the benefits of Semantic Web technologies' flexibility are brought directly to the end user, the business user. The business manager can bring together new data sets for analysis today, rather than a week for now. An analyst can setup triggers and alerts to monitor for key business indicators today, rather than waiting 3 months. A senior scientist can begin looking for correlations within ad-hoc sets of data today, rather than next year.
It's All About the Data Model
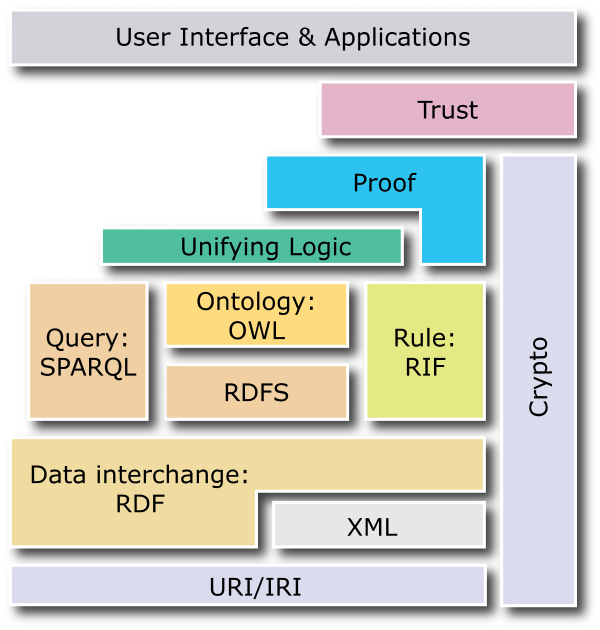
There is a new data model called RDF—the data model of the Semantic Web—which combines the best of both worlds: the flexibility of a spreadsheet and the manageability and data integrity of a relational database. Based on standards set by the World Wide Web Consortium (W3C) to enable data combination on the Web, RDF defines each data cell by the entity it applies to (row) and the attribute it represents (column). Each cell is self-describing and not locked into a grid, in other words the data doesn't have to be "regular". Further, it has formal operations that can be performed on it, much like relational algebra, but clearly at a more atomic level.




{kind=link}
Recent Comments