Introduction
Over the past two years, my good friend and coworker Elias Torres has been blogging at an alarming rate about a myriad of technology topics either directly or indirectly related to the Semantic Web: SPARQL, Atom, Javascript, JSON, and blogging, to name a few. Under his encouragement, I began blogging some of my experiences with SPARQL, and two of our other comrades, Ben Szekely and Wing Yung, have also started blogging about semantic technologies. And in September, Elias, Wing and Ben blogged a bit about Queso, our project which combines Semantic Web and Web 2.0 techniques to provide an Atom-powered framework for rapid development and deployment of RDF-backed mash-ups, mash-ins, and other web applications.
But amidst all of this blogging, we've all been working hard at our day jobs at IBM, and we've finally reached a time when we can talk more specifically about the software and infrastructure that we've been creating in recent years and how we feel it fits in with other Semantic Web work. We'll be releasing our components as part of the IBM Semantic Layered Research Platform open-source project on SourceForge over the next few months, and we'll be blogging examples, instructions, and future plans as we go. In fact, we've already started with our initial release of the Boca RDF store, which Wing and Matt have blogged about recently. I'll be posting a roadmap/summary of the other components that we'll be releasing in the coming weeks later today or tomorrow, but first I wanted to talk about our overall vision.
Background
The family of W3C-endorsed Semantic Web technologies (RDF, RDFS, OWL, and SPARQL being the big four) have developed under the watchful eyes of people and organizations with a variety of goals. It's been pushed by content providers (Adobe) and by Web-software organizations (Mozilla), by logicians and by the artificial-intelligence community. More recently, Semantic Web technologies have been embraced for life sciences and government data. And of course, much effort has been put towards the vision of a machine-readable World Wide Web—the Semantic Web as envisioned by Tim Berners-Lee (and as presented to the public in the 2001 Scientific American article by Berners-Lee, Jim Hendler, and Ora Lassila).
Our adtech group at IBM first took note of semantic technologies from the confluence of two trends. First, several years ago we found our work transitioning from the realm of DHTML-based client runtimes on the desktop to an annotation system targeted at life-sciences organizations. As we used XML, SOAP, and DB2 to develop the first version of the annotation system along with IBM Life Sciences, we started becoming familiar with the enormity of the structured and unstructured, explicit and tacit data that abounds throughout the life sciences industry. Second, it was around the same time that Dennis Quan—a former member of our adtech team—was completing his doctoral degree as he designed, developed, and evangelized Haystack, a user-oriented information manager built on RDF.
Our work continued, and over the next few years we became involved with new communities both inside and outside of IBM. Via a collaboration with Dr. Tom Deisboeck, we became involved with the Center for the Development of a Virtual Tumor (CViT) and developed plans for a semantics-backed workbench which cancer modelers from different laboratories and around the world could use to drive their research and integrate their work with that of other scientists. We met Tim Clark from the MIND Center for Interdisciplinary Informatics and June Kinoshita and Elizabeth Wu of the Alzheimer Research Forum as they were beginning work on what would become the Semantic Web Applications in Neuromedicine (SWAN) project. We helped organize what has become a series of internal IBM semantic-technology summits, such that we've had the opportunity to work with other IBM research teams, including those responsible for the IBM Integrated Ontology Development Toolkit (IODT).
All of which (and more) combines to bring us to where we stand today.
Our Vision
While we support the broad vision of a Semantic World Wide Web, we feel that there are great benefits to be derived from adapting semantic technologies for applications within an enterprise. In particular, we believe that RDF has several very appealing properties that position it as a data format of choice to provide a flexible information bus across heterogeneous applications and throughout the infrastructure layers of an application stack.
Name everything with URIs
When we model the world with RDF, everything that we model gets a URI. And the attributes of everything that we model get URIs. And all the relationships between the things that we model get URIs. And the datatypes of all the simple values in our models get URIs.
URIs enable selective and purposeful reuse of concepts. When I'm creating tables in MySQL and name a table album, my table will share a name with thousands of other database tables in other databases. If I have software that operates against that album table, there's no way for me to safely reuse it against album tables from other databases. Perhaps my albums are strictly organized by month, whereas another person's album table might contain photos spanning many years. Indeed, some of those other album tables might hold data on music albums rather than photo albums. But when I assert facts about http://thefigtrees.net/lee/ldf-card#LDF, there's no chance of semantic ambiguity. Anyone sharing that URI is referencing the same concept that I am, and my software can take advantage of that. The structured, universal nature of URIs guarantees that two occurrences of the same identifier carry the same semantics.
While URIs can be shared and reused, they need not be. Anyone can mint their own URI for a concept, meaning that identifier creation can be delegated to small expert groups or to individual organizations or lines of business. Later, when tools or applications encounter multiple URIs that may actually reference the same concept, techniques such as owl:sameAs or inverse-functional properties can allow the URIs to be used interchangeably.
Identifying everything with URIs has other benefits as well. Many URIs (especially HTTP or LSID URIs) can be resolved and dereferenced to discover (usually in a human-readable format) their defined meaning. The length of URIs is also an advantage, albeit a controversial one. URIs are much longer than traditional identifiers, and as such they often are or contain strings which are meaningful to humans. While software should and does treat URIs as opaque identifiers, there are very real benefits to working with systems which use readable identifiers. At some level or another, all systems are engineered, debugged, and maintained by people, and much of the work of such people is made significantly simpler when they can work with code, data, and bug reports which mention http://example.org/companies/acme/acme-explosives rather than companyId:80402.
RDF: A flexible and expressive data model
By representing all data as schema-less triples comprising a data graph, RDF provides a model which is expressive, flexible, and robust. The graph model frees the data modeler and/or application developer from defining a schema a priori, though RDF Schema and OWL do provide the vocabulary and semantics to specify the shape of data when that is desirable. And even when the shape of data has been prescribed, new, unexpected and heterogeneous data can be seamlessly incorporated into the overall data graph without disturbing the existing, schema-conformant data.
Furthermore, a graph-based data model allows a more accurate representation of many entities, attributes, and relations (as opposed to the relational model or (to a lesser extent) XML's tree/infoset model). Real objects, concepts, and processes often have a ragged shape which defies rigid data modeling (witness the pervasiveness of nullable columns in relational models) but is embraced by RDF's graph model. And while all common data models force certain artificial conventions (e.g. join tables) onto the entities being modeled, a directed, labeled graph can better handle common constructs such as hierarchical structures or homogeneous, multi-valued attributes.
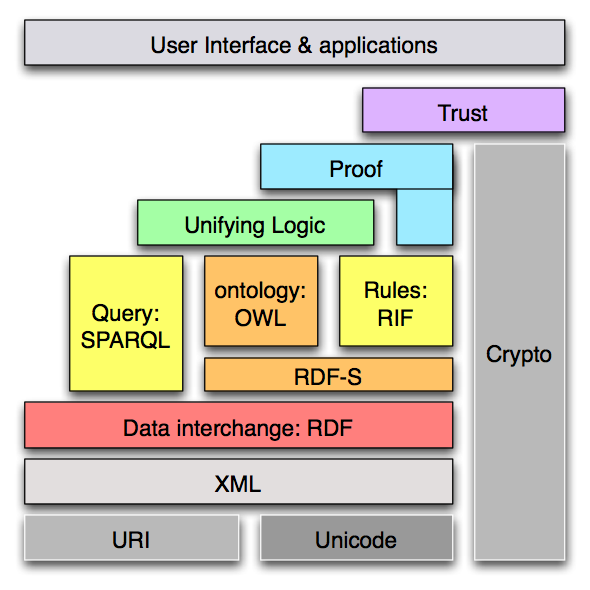
The Semantic Web layer cake
Thankfully, RDF does not exist in a vacuum. Instead, it is and has always been a part of a larger whole, building upon lower-level infrastructure and laying the groundwork for more sophisticated capabilities including query, inference, proof, and trust. OWL powers consistency checking of rules and of instance data. Rules languages (e.g. SWRL or N3) enable reasoning over existing RDF data and inference of new data. And SPARQL provides a query language which combines the flexibility of RDF's data model with the ability to query data sources scattered across the network with a single query. The upper layers of abstraction in this stack are largely still in development, but the beauty of this modular approach is that we can begin benefiting from the lower layers while areas such as trust and proof are still evolving.
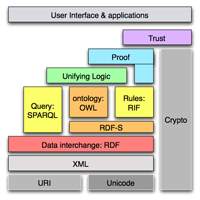
A standard lingua franca for machines
RDF is an open W3C specification. So is OWL. And so is SPARQL. The Rules Interchange Format (RIF) working group is standardizing rule interoperability within the semantic-technologies arena. So what do we have here? We have a flexible data model which can adjust effortlessly to unexpected data sources and new shapes of data and which has a high degree of expressivity to model real-world objects. The data model can be queried in a network-aware manner. It can be organized in ontologies, reasoned over, and it can have new data inferred within it. And all of this is occurring via a set of open, standard technologies. At IBM, we look at this confluence of factors and come to one conclusion:
RDF is uniquely positioned as a machine-readable lingua franca for representing and integrating relational, XML, proprietary, and most other data formats..
One particularly appealing aspect of this thesis is that it does not require that all data be natively stored as RDF. Instead, SPARQL can be used in a heterogeneous environment to query both native RDF data and data which is virtualized as RDF data at query time. Indeed, we've exploited that paradigm before in our demonstrations of using SPARQL to create Web 2.0-style mash-ups.
The Semantic Web in the enterprise
These benefits of semantic technologies could (and will) do great things when applied to the Web as we know it. They can enable more precise and efficient structured search; they can lower the silo walls that separate one Web site's data from the next; they can drive powerful software agents that perform sophisticated managing of our calendars, our business contacts, and our purchases. For these dreams to really come into their own, though, requires significant cross-organization adoption to exploit the network effect on which semantic web technologies thrive. I have little doubt that the world is moving in this direction (and in some areas much more quickly than in others), but we are not there yet.
In the meantime, we believe that there is tremendous value to be derived from adopting semantic technologies within the enterprise. Over the past few years, then, we've sought to bring the benefits enumerated above into the software components that comprise a traditional enterprise application stack. The introduction of semantic technologies throughout the application stack is an evolutionary step that enhances existing and new applications by allowing the storage, query, middleware, and client-application layers of the stack to more easily handle ragged data, unanticipated data, and more accurate abstractions of the domain of discourse. And because the components are all semantically aware, the result is a flexible information bus to which new components can be attached without being tied down by the structure or serialization of content.
Anywhere and everywhere
Once we've created an application stack which is permeated with semantic technologies, we can develop applications against it in many, many different settings. Some of this is work that we've been engaged in at IBM, and much of it is work that has engrossed other members of the community. But all of it can benefit when semantics are pushed throughout the infrastructure. Some of the possibilities for where we can surface the benefits of semantic technologies include:
On the Web. We can quickly create read-only Web integrations using SPARQL within a Web browser. Or we can use Queso to create more full-featured Web applications by leveraging unified RDF storage and modularity along with the simplicity of the Atom Publishing Protocol. Or we can leverage community knowledge in the form of semantic wikis.
Within rich client applications. Full-featured desktop applications can be created which take advantage of semantic technologies. To do this we must develop new programming models based on RDF and friends, and use those models to create rich environments capable of highly dynamic and adaptive user experiences. We've done work in this direction with a family of RCP-friendly data-management and user interfaces libraries named Telar, and many of the ideas are shared by the Semedia group's work with DBin.
Amidst traditional desktop data. Whether in the form of Haystack, Gnowsis, or perhaps some other deliverables from the Nepomuk consortium, there are tremendous amounts of semi-structured and unstructured data lurking in the cobwebbed corners of our desktops. Emails, calendar appointments, contacts, documents, photographs... all can benefit from semantic awareness and from attaching to a larger semantic information bus that integrates the desktop with content from other arenas.
Where do we go from here?
We're going to be working hard inside IBM, with our customers and business partners, and within the semantic web community to realize all these benefits I've written about. We'd like to take advantage of the myriad of other open-source semantic components that already exist and are being built, and we'd like others to take advantage of our software. We believe the time is right for a semantic-technologies development community to work together to create interoperable software components. We also think that the time is ripe to educate industry leaders and decision makers as to the value proposition of semantic web technologies (and at the same time, to dispel many of the mistaken impressions about these technologies). To this end, Wing and I have joined the fledgling W3C Semantic Web Education and Outreach interest group (SWEO), where we look forward to working with other semantic-technology advocates to raise awareness of the benefits and availability of semantic web technologies and solutions.